如何高效比较类型结构?从 TS 的类型系统到结构 Trie 优化
先问大家一个问题,给定俩个对象该怎么“快速”比较其是否等价?
转字符串比较吗?如果参数顺序不一致呢 遍历吗?可以 但如果嵌套层级过深呢? 好似俩颗树结构比较 深度优先遍历?可以? 如果项目中仅仅是一处比较,暂时这么写当然没有问题,倘若存在很多很多很多组对象呢,届时就达不到快速的基准了。
可能会纳闷,为什么要问这个问题,这个跟主题 ts 类型有什么关联
举个很常见的示例,函数不同情况返回不同参数,猜猜他的返回类型会是什么
const demo = () => {
if (1) {
return {
name: 'xxx',
age: 1
}
}
else {
return 1
}
return {
age: 2,
name: "wwww"
}
}
type DemoReturn = ReturnType<typeof demo>
// 输入:
// 1 | {
// name: string;
// age: number;
// }
通过获取函数返回类型,观察其结果类型,你会惊讶的发现,其结果并不是如下所示
DemoReturn = {
name: string,
age: number
} | 1 | {
age: number,
name: string
}
这正是因为 ts 内部联合类型进行了比较并删除了相同类型
todo:
- 显示联合类型不会自动展开计算结果譬如
TypeA | TypeB- 而隐式联合类型会进行联合运算,譬如函数返回类型
那么回归开头的问题,既然 ts 内部也有对象类型比较, 他是否解决了上面抛出了一系列问题,又是否用到了什么黑魔法, 一起来揭开他神秘的面纱
Ts 类型比较的现状
ts会为所有基础类型维护全局map存储,相同字面量指向同一Type引用ts会遍历联合类型节点,为其互相比较- 如果是对象类型比较,还需要额外遍历对象判断类型兼容
- 如果遍历对象的某项类型也是对象,还需要额外深度遍历
- 然后为联合类型缓存比较结果 id
function removeSubtypes(types: Type[], hasObjectTypes: boolean): Type[] | undefined {
// [] and [T] immediately reduce to [] and [T] respectively
if (types.length < 2) {
return types;
}
const id = getTypeListId(types);
const match = subtypeReductionCache.get(id);
if (match) {
return match;
}
const len = types.length;
let i = len;
let count = 0;
while (i > 0) {
i--;
const source = types[i];
if (hasEmptyObject || source.flags & TypeFlags.StructuredOrInstantiable) {
for (const target of types) {
if (source !== target) {
// 判断类型是否相同兼容
if (
isTypeRelatedTo(source, target, strictSubtypeRelation) && (
!(getObjectFlags(getTargetType(source)) & ObjectFlags.Class) ||
!(getObjectFlags(getTargetType(target)) & ObjectFlags.Class) ||
isTypeDerivedFrom(source, target)
)
) {
orderedRemoveItemAt(types, i);
break;
}
}
}
}
}
subtypeReductionCache.set(id, types);
return types;
}
removeSubtypes 会俩俩比较类型,相同类型结构会被删除
假如存在多个联合类型,类型比较会存在指数级复杂度
而
isTypeRelatedTo内部调用链-> checkTypeRelatedTo -> isRelatedTo
isRelatedTo 是 TypeScript 类型系统的核心函数,用于判断两个类型之间的关系
/**
* Compare two types and return
* * Ternary.True if they are related with no assumptions,
* * Ternary.Maybe if they are related with assumptions of other relationships, or
* * Ternary.False if they are not related.
*/
function isRelatedTo(originalSource: Type, originalTarget: Type, recursionFlags: RecursionFlags = RecursionFlags.Both, reportErrors = false, headMessage?: DiagnosticMessage, intersectionState = IntersectionState.None): Ternary {
// 同一类型引用
if (originalSource === originalTarget) return Ternary.True;
// origin 对象类型, target 为基础类型
// 源类型是对象类型(如 { x: number } 或 Date)
// 目标类型是原始类型(如 string, number, boolean)
if (originalSource.flags & TypeFlags.Object && originalTarget.flags & TypeFlags.Primitive) {
return Ternary.False;
}
// target 和 source 都是结构对象
if (source.flags & TypeFlags.StructuredOrInstantiable || target.flags & TypeFlags.StructuredOrInstantiable) {
const isPerformingExcessPropertyChecks = !(intersectionState & IntersectionState.Target) && (isObjectLiteralType(source) && getObjectFlags(source) & ObjectFlags.FreshLiteral);
if (isPerformingExcessPropertyChecks) {
// 判断 target 上是否有 source 的多余属性
if (hasExcessProperties(source as FreshObjectLiteralType, target, reportErrors)) {
return Ternary.False;
}
}
// 是否有公共属性
if (isPerformingCommonPropertyChecks && !hasCommonProperties(source, target, isComparingJsxAttributes)) {
return Ternary.False;
}
const skipCaching = source.flags & TypeFlags.Union && (source as UnionType).types.length < 4 && !(target.flags & TypeFlags.Union) ||
target.flags & TypeFlags.Union && (target as UnionType).types.length < 4 && !(source.flags & TypeFlags.StructuredOrInstantiable);
const result = skipCaching ?
unionOrIntersectionRelatedTo(source, target, reportErrors, intersectionState) :
recursiveTypeRelatedTo(source, target, reportErrors, intersectionState, recursionFlags);
if (result) {
return result;
}
}
return Ternary.False;
}
recursiveTypeRelatedTo 内部调用链 -> structuredTypeRelatedTo -> structuredTypeRelatedToWorker -> propertiesRelatedTo 关键代码如下:
这段代码是
TypeScript类型系统中对象类型属性比较的核心部分,主要处理两个对象类型之间属性级别的兼容性检查:// 遍历源类型的所有属性 // 检查源属性是否存在于目标类型中 if (isObjectLiteralType(target)) { for (const sourceProp of excludeProperties(getPropertiesOfType(source), excludedProperties)) { if (!getPropertyOfObjectType(target, sourceProp.escapedName)) { const sourceType = getTypeOfSymbol(sourceProp); if (!(sourceType.flags & TypeFlags.Undefined)) { return Ternary.False; } } } } // 类型比较兼容检查 const properties = getPropertiesOfType(target); const numericNamesOnly = isTupleType(source) && isTupleType(target); for (const targetProp of excludeProperties(properties, excludedProperties)) { const name = targetProp.escapedName; if (!(targetProp.flags & SymbolFlags.Prototype) && (!numericNamesOnly || isNumericLiteralName(name) || name === "length") && (!optionalsOnly || targetProp.flags & SymbolFlags.Optional)) { const sourceProp = getPropertyOfType(source, name); if (sourceProp && sourceProp !== targetProp) { const related = propertyRelatedTo(source, target, sourceProp, targetProp, getNonMissingTypeOfSymbol, reportErrors, intersectionState, relation === comparableRelation); if (!related) { return Ternary.False; } result &= related; } } } return result; }而
propertyRelatedTo内部会调用isRelatedTo, 形成深度有限遍历
有些敏锐的小伙伴可能发现了 ts 这一套比较逻辑的痛点
- 深度遍历比较,等同遍历整棵树,时间复杂度 O(n²),尤其在嵌套复杂结构中开销巨大
- 斌且没有复用的概念,相似结构仍需重复比较
- 无法利用已处理结构进行快速匹配与缓存。 比如下面示例
type O_1 = { name: string, age: number } type O_2 = { name: string, age: number, other: any }当
O_1解析完成,O_2无法复用O_1的结果,重新解析无效开销
- 无法利用已处理结构进行快速匹配与缓存。 比如下面示例
最初设想是:位标识快速比较
我希望每个对象类型有一个唯一标识,通过判断标识可以快速比较类型
- 将对象每个参数拼接 typeKind, 通过hash函数生成一组二进制
结构中所有属性hash_id聚会成一个标识位( flag = hash_id) - 那么当存在联合类型比较,一方遍历对象参数生成 flag 中
- flag_1 & hash_id 就能感知,当前参数是否被比较类型包含
然鹅问题
- 位编码只能包含有限参数信息,字段过多易冲突
- 哈希映射不可逆,不支持嵌套结构
- 无法表达子结构复用与结构相似性
我的方案:结构字段映射 + 前缀 Trie
为了解决上面的问题,我最终采取一种基于前置树的比较机制。通过将对象类型结构抽象,使得对象类型的比较从递归演变为路径匹配,以实现复用以及更好的性能
关键步骤:
- 字段唯一 ID 映射(
fieldMap)- 所有字段名在全局映射为递增 fieldId:如 name → 1, age → 2,避免了字符串比较
- 该映射确保结构中字段排序稳定,利于结构规范化
- 结构字段规范化 + 排序
- 对象结构按 fieldId 排序,形成结构[fieldId, typeKind]签名
- 排序后的结构作为 Trie 的路径,用于复用判断
- 结构 Trie 构建与比较
- 每条结构路径构成 Trie 的一条分支,末端节点打上唯一结构标识 flagId
- 同结构对象拥有相同 flagId,快速判断是否等价
展开来说:
示例一:字段顺序不同的相同结构
type O1 = { name: string, age: number }
type O2 = { age: number, name: string }
- 初次解析 O1,构建 fieldMap:
fieldMap = { name: 1, age: 2 } - 排序组装结构签名
[name{ fieldId_1, type_kind }, age{ fieldId_2, type_kind }] - 构建 Trie: ```less root └── name:string (1) └── age:number (2) → flagId = 2
4. 解析 O2 时:
字段排序后仍为 `[name{ fieldId_1, type_kind }, age{ fieldId_2, type_kind }]`,Trie 路径匹配成功,得到相同 flagId = 2
结构等价
示例二:结构嵌套的复用复识别
```typescript
type O = { name: string }
type O1 = { name: string, obj: { name: string } }
type O2 = { obj: O, name: string }
type O3 = { age: number, obj: O, name: string }
字段映射fieldMap:
fieldMap = { name: 1, obj: 2, age: 3 }
结构构建与复用如下:
| 类型 | 结构签名(fieldId 排序) | 子结构复用 | 对应 flagId |
|---|---|---|---|
| O | [name{ fieldId_1, type_kind }] | 无 | 1 |
| O1 | [name{ fieldId_1, type_kind }, obj { fieldId_2, obj_flagId }] | obj 复用 | 2 |
| O2 | [name{ fieldId_1, type_kind }, obj { fieldId_2, obj_flagId }] | obj 复用 | 2 |
| O3 | [name{ fieldId_1, type_kind }, obj { fieldId_2, obj_flagId }, age { fieldId_3, type_kind }] | obj 复用 | 3 |
最终 Trie 树形如下:
root
└── name:string (1)
└── obj:{flag=1} (2)
└── age:number (3) → flagId = 3
其中类型标识是在解析到字面量对象词法分析的阶段生成,因此后续不会有额外遍历开销
这样联合类型判断就可以转换为
type Demo = O1 | O2 | O3;
// [flag_2, flag_2, flag_3]
// 简单去重就能就能得到结果 -> O1 | O3
交叉类型判断
type Test = O3 & O2 & O1;
其实有了前置树后的设计也会好操作很多
- 对于字面量对象结构,交叉类型判断可简化为路径包含关系判断。
- 对于复杂类型(泛型,条件类型等),可在类型调用归一化后,匹配前置树,再进行比较。
具体步骤:
- 根据 flagId 去重
- 根据 flagId 排序,从大到小, 反向查找路径;
- 路径回收,若查询到共享子路径(匹配flagId),表示为结构包含关系 抽象来说就是类型对应路径的覆盖集合
优势对比:
| 传统递归结构比较(如 TS 实现) | Trie 结构对比方案 |
|---|---|
| 深度递归比较,开销高 | 路径匹配,时间复杂度近似 O(n) |
| 无结构复用 | 子结构按路径自动复用 |
| 对象等价需逐字段判断 | 结构拥有唯一 flagId,直接对比 |
| 无嵌套优化能力 | 嵌套结构自动哈希压缩 |
| 不适合动态结构缓存 | 支持缓存、去重、路径剪枝 |
隐藏类
因为前置树方案与 V8 引擎中(Hidden Class)隐藏类机制高度相似,也顺手提上一嘴吧
总所周知哈,javascript 是动态类型语言因此非常的灵活,与静态类型语言不同,js 对象可以动态修改比如下面 age 属性, 这使得无法确认其静态结构,与其相关的内存布局。
const obj = {
name: 'mingrui',
address: 'xxxx'
}
obj.age = "25"
obj.age = {
record: {}
}
为了更方便理解,想象一下自己经营「物品托管所」,而你作为店铺老板,为了方便管理物品,自然的会准备本小本子 记录有哪些物品以及对应存放位置。
最初的 obj 看起来是这样的:
const obj = {
name: 'mingrui',
address: 'xxxx'
}
此时它的「存储表(store_table)」为
store_table {
name: ptr('存储位置')
age: ptr('存储位置')
}
这时有人需要更新存储 age = { xx: ‘xx’ }, 对象结构发生变化,原来的“托管所”存储位置不再适用, 为了不失去这个客户,你打算忽悠身边朋友也来做物品托管,让其店铺代存,此时物品编号映射表为
store_table {
name: ptr('存储位置')
age: storeA_table
}
storeA_table {
xx: ptr('存储位置')
}
这时如果客户需要获取存储物品 age 则需要多一层,联系其他店铺获取。
最开始这种层级式的托管是可以接受的,但随着结构变更越来越频繁,你托管关联的「物品托管所」也越来越多,就会出现问题了:
多层查找、多级托管,极大增加了查找开销。
通过上面你可能敏锐的发现,如果事先就知道需要存储哪些物品,物品直接关联的位置也就没有这些开销了(静态化
那么怎么让动态存储趋于静态化呢?
隐藏类的本质:模拟静态结构 核心作用:
- 记录属性偏移量:为每个属性分配固定的内存偏移地址
- 结构共享复用:相同结果共享同一个隐藏类实例,复用属性偏移地址
传统hash表 假设访问 obj.age.xx, 对应流程
value = hash_table['age'].hash_table['xx']
因为不感知属性在 hash 表中的具体位置,每次获取都需要:
- 计算hash -> 定位桶 -> 处理冲突
隐藏类流程
const obj = {}
obj.propertieA = 1
obj.propertieB = 1
struct obj {
hiddenClass -> hiddenClass_A // 隐藏类指针
properties -> ptr
}
hiddenClass_A {
propertieA: offect 0 // 偏移量
}
hiddenClass_A.add(propertieB)
hiddenClass_B {
propertieB: offect 1 // 偏移量
}
// hiddenClass_A -> hiddenClass_B
// 更新 struct_obj hiddenClass 指针为hiddenClass_B
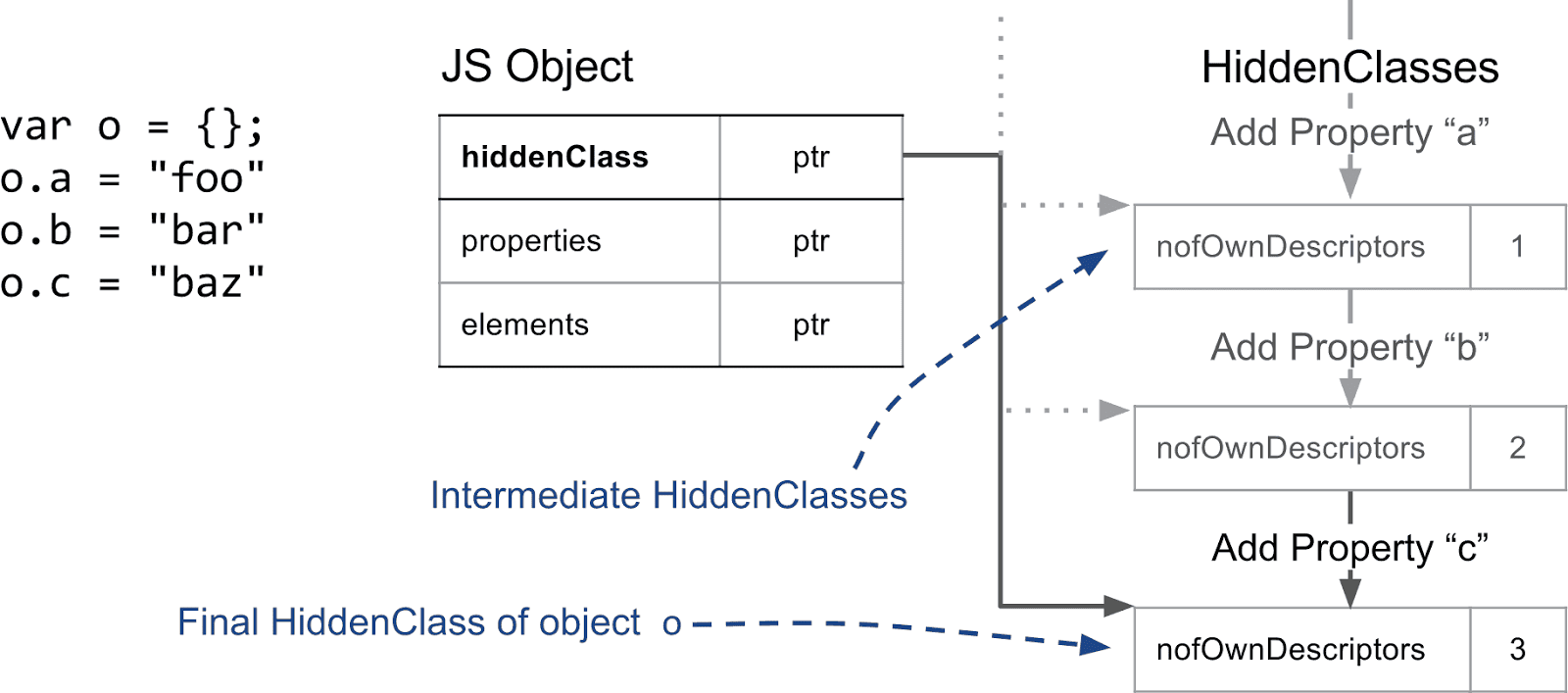 那么其属性访问流程:
那么其属性访问流程:
- 通过获取 obj 隐藏类指针地址以及 属性偏移位置 propertieB 为 1
- 属性值的地址 = 对象结构指针地址 + 属性值偏移位置
- 获取值
有三种不同的命名属性类型:对象内、快速和慢速/字典。
| 属性类型 | 存储方式 | 访问速度 | 适用场景 |
|---|---|---|---|
| 对象内属性 | 内联在对象内存块中 | 极快(单次加法) | 结构稳定时 |
| 快速属性 | 属性存储区 + 隐藏类描述符 | 快(需查找隐藏类) | 结构轻微变化时 |
| 慢速属性 | 独立哈希表 | 慢(哈希计算 + 冲突处理) | 结构频繁变化时 |
所以每当对象创建,申请内存上都会预留一些空间,而隐藏类事先计算改好了属性偏移量就可以消费对应内存, 当空间不够用时,就会创建hash表退化为慢速属性
衍生问题
- 预编译阶段,此法环境创建的VO对象是否有隐藏类的机制?
- 闭包对象是否也具备隐藏类优化?
动机?
可能有人会好奇:“写代码写到研究类型结构比较,图啥?你卷你*呢”
其实这一切都源自我在做的一个项目 —— 类型逆向推导。本质是根据字面量的结构与其具体消费值,自动还原其在 TypeScript 中的最精确类型。 (其中联合推断碰到类型比较的问题,当时还好奇ts会不会有什么黑魔法借鉴来着)
举个栗子
例如下面函数,通过分析字面量以及if判断,既可以推导 props.type 是 number 和 string 的联合类型 同样的可以推导obj, 而props.obj 与obj同一引用,因此可以得到完整的props:
function demo(props) {
const { type } = props
let obj = props.obj
if (type === 1) {}
if (type === "xx") {}
obj.a = 1
return obj
}
// 推断结果:
type Props = {
type: number | string,
obj: {
a: number
}
}
亦或者是这种典型的条件返回函数,根据条件分支,反推出函数的重载类型:
function demo(props) {
if (type === 1) return 1
else if(type === "x") return 'string'
return ['xxx']
}
// 推断结果
function demo(props: unknown): string[];
function demo(props: string): string;
function demo(props: object): number;
demo("x") // -> string
demo({}) // -> number
demo(1) // -> string[]
当然真实项目远不止这些简单的场景:
- 跨模块,跨多层作用域
- 泛型,条件兼容
- 显示标注类型与推断类型兼容
- 等等
那么为什么想做这玩意?
最开始仅仅是因为为项目修复 ts 警告时,修复过程过于机械化,便想着为其注入灵魂让其自动推导
仅仅推导函数类型是不够了,其中不乏有一些设想:
- 我觉得可以让推导配合
ts做到绝对的静态,所见即所得- 无法推导的动态数据用
ts标注比如(接口,文件获取,JSON转换等 - 通过标识类型推导其他类型
- 无法推导的动态数据用
- 有了具体类型,可以搭配自动化生成对应单侧
- 然鹅总所周知,
ts并不存在运行态,无法做到运行时校验,市面上虽然有相关的库, 都有有一些缺点:- 需要入侵项目
- 增加额外的运行开销
- 既然有单侧和
e2e何不假想,本地运行态校验,而不影响预发线上环境呢- 类型推导过模块后会生成缓存文件类似.umi
- 开发一款插件,代理模块资源,匹配上缓存文件,走代理调用外层包一层类型推断
- 类型推断根据缓存文件以及运行数据断言
- 类型断言完全不影响开发心智,无需额外增加代码,也不影响其他环境
- 然鹅总所周知,
- 因为推断过程可以获取到足够多的信息,是可以感知,哪些函数不合理
- 比如修改源数据
- 组件内创建传函数等
- 但这一块设想因为 ai吃掉了很大一部分,倒希望利用解析到足够多的信息怎么加入他们
进度情况
参考文章: